More and more teams are using large language models to refactor legacy code, extract modules, and pay down technical debt. The pitch is compelling: paste your code into an LLM, describe what you want, and get a clean rewrite back. But there is a hidden variable that determines whether this workflow costs you $2 or $200, and whether it works at all. That variable is token count.
Tokens: The Currency of Every LLM Interaction
Large language models do not read source code the way humans do. They break text into sub-word units called tokens. A single Python keyword like def might be one token, while a longer variable name like calculate_total_revenue could be three or four. Whitespace, comments, docstrings, import statements: they all consume tokens.
Every model has a hard ceiling on how many tokens it can process in a single request, its context window. GPT-4o caps at 128k tokens. Claude at 200k. Sounds generous, until you realize a medium-sized Python backend with 50 files can easily exceed 80,000 tokens before you have even written your prompt.
The Refactoring Problem
Refactoring is uniquely punishing when it comes to tokens. Unlike writing a new function from a short description, refactoring requires the model to understand the existing code first. That means you need to feed it:
- The file or module you want to refactor (the target).
- Every file that imports from or is imported by that module (the dependencies).
- Tests that validate the current behavior.
- Your instructions describing the desired change.
For a tightly coupled module in a legacy codebase, this dependency chain alone can consume tens of thousands of tokens. And here is the critical point: the more tangled and complex your code is, the code that most needs refactoring, the more tokens it takes to describe it to an LLM.
The irony: The codebases that benefit the most from AI-assisted refactoring are the ones that are the most expensive to refactor with AI, because their high complexity translates directly into high token counts.
How High Token Counts Drive Up Costs
LLM APIs bill per token, both input and output. When you are refactoring, the cost equation works against you in three ways:
- Large input context. You are sending thousands of lines of existing code as context. Every line of a 500-line module with inline comments and verbose docstrings is money spent.
- Iterative passes. Refactoring rarely works in a single shot. The model's first attempt might miss an edge case or break an import chain. Each follow-up prompt re-sends the full context, doubling or tripling the total tokens processed.
- Wasted tokens on noise. Blank lines, commented-out code, unused imports, and boilerplate: none of these carry semantic meaning, but they all consume tokens and dilute the model's attention.
A practical example: refactoring a single 400-line Python module with 3 dependent files might consume ~25,000 input tokens per attempt. If it takes 4 iterations to get a clean result, that is 100,000 input tokens plus output, easily $1-3 on GPT-4o for a single module. Multiply that across a 20-module refactoring project, and you are looking at real engineering budget.
Context Window Overflows Kill Quality
Cost is only half the problem. When your code exceeds the model's context window, you are forced to make trade-offs that directly degrade output quality:
- Truncating context means the model cannot see the full dependency chain, leading to broken imports and incorrect function signatures in the refactored output.
- Splitting across multiple prompts loses cross-file awareness. The model refactors module A without knowing that module B depends on a function you just renamed.
- Summarizing instead of including source code strips away the exact details (type hints, error handling, edge cases) that matter most during a refactor.
The result is that high-token-count codebases produce lower-quality LLM refactoring output, which requires more manual review and correction, which defeats the purpose of using an LLM in the first place.
Knowing Your Token Count Changes the Game
This is where token counting stops being a curiosity and becomes a prerequisite. Before you start any LLM-assisted refactoring, you need to know:
- Which modules are the heaviest? A module with 8,000 tokens is a very different refactoring task than one with 800. Knowing this upfront lets you prioritize and plan.
- Where is the noise? If 30% of a module's tokens come from comments and dead code, cleaning those out before prompting the LLM can save significant cost and improve output quality.
- Will this fit in a single pass? If your target module plus its dependencies exceed 100k tokens, you know in advance that you will need to break the work into stages rather than discovering it after a failed API call.
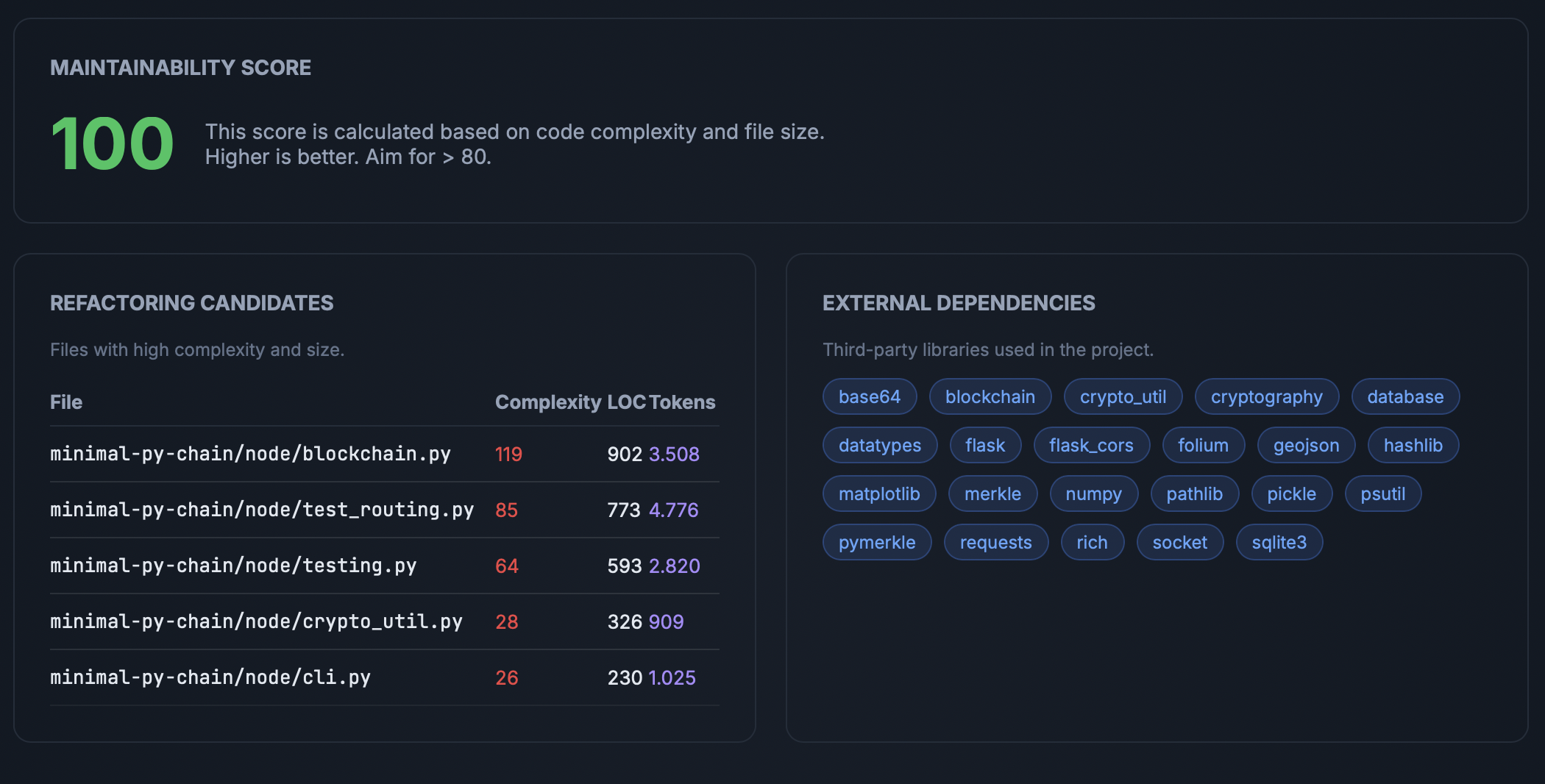
How Creview helps: When you upload a project to Creview, you get the real token count of every module in your codebase instantly. Combined with the dependency graph, you can see exactly which files need to be included for a refactoring prompt and whether the total will fit within your model's context window before you spend a single API dollar.
A Smarter Refactoring Workflow
Armed with accurate token counts, you can adopt a far more efficient approach:
- Audit first. Use Creview's dashboard to identify high-token modules and their dependency chains. Target isolated, high-complexity modules for the biggest impact.
- Clean before prompting. Strip dead code, unused imports, and excessive comments. This reduces token consumption and focuses the model on what matters.
- Budget your context. Allocate tokens deliberately: source code, dependencies, tests, and instructions. Know exactly how much room you have left for the model's response.
- Validate structurally. After the LLM produces output, use the AST visualizer to verify that the refactored code maintains the correct structure and dependency relationships.
Token counting is not a nice-to-have metric. For any team using LLMs as part of their engineering workflow, it is a fundamental cost and quality control. The teams that measure it will ship faster and spend less. The teams that ignore it will keep wondering why their AI refactoring bills are so high and their results so inconsistent.
Analyze Your Token Counts →